YOLOv4
[2004.10934] YOLOv4: Optimal Speed and Accuracy of Object Detection (arxiv.org)
Abstract 摘要
There are a huge number of features which are said to improve Convolutional Neural Network (CNN) accuracy. Practical testing of combinations of such features on large datasets, and theoretical justification of the result, is re- quired. Some features operate on certain models exclusively and for certain problems exclusively, or only for small-scale datasets; while some features, such as batch-normalization and residual-connections, are applicable to the majority of models, tasks, and datasets. We assume that such universal features include Weighted-Residual-Connections (WRC), Cross-Stage-Partial-connections (CSP), Cross mini-Batch Normalization (CmBN), Self-adversarial-training (SAT) and Mish-activation. We use new features: WRC, CSP, CmBN, SAT, Mish activation, Mosaic data augmentation, CmBN, DropBlock regularization, and CIoU loss, and com- bine some of them to achieve state-of-the-art results: 43.5% AP (65.7% AP50) for the MS COCO dataset at a real- time speed of ∼65 FPS on Tesla V100. Source code is at https://github.com/AlexeyAB/darknet.
据说有大量特征可以提高卷积神经网络 (CNN) 的准确性。 需要在大型数据集上对这些特征的组合进行实际测试,并对结果进行理论论证。 某些特征专门针对某些模型,专门针对某些问题,或仅针对小规模数据集; 而一些特性,如批量归一化和残差连接,适用于大多数模型、任务和数据集。我们假设这些通用(universal)特征包括加权残差连接 (WRC)、跨阶段部分连接 (CSP)、交叉小批量归一化 (CmBN)、自我对抗训练 (SAT) 和 Mish 激活。 我们使用新功能:WRC、CSP、CmBN、SAT、Mish 激活、Mosaic 数据增强、DropBlock 正则化和 CIoU 损失,并结合其中的一些来实现最先进的结果:在 Tesla V100 上以 ~65 FPS 的实时速度用于 MS COCO 数据集,结果为43.5% AP(65.7 % AP50) 。 源代码位于 https://github.com/AlexeyAB/darknet。
Introduction 引言
The majority of CNN-based object detectors are largely applicable only for recommendation systems. For example, searching for free parking spaces via urban video cameras is executed by slow accurate models, whereas car collision warning is related to fast inaccurate models. Improving the real-time object detector accuracy enables using them not only for hint generating recommendation systems, but also for stand-alone process management and human input reduction. Real-time object detector operation on conven- tional Graphics Processing Units (GPU) allows their mass usage at an affordable price. The most accurate modern neural networks do not operate in real time and require large number of GPUs for training with a large mini-batch-size. We address such problems through creating a CNN that op- erates in real-time on a conventional GPU, and for which training requires only one conventional GPU.
大多数基于 CNN 的对象检测器在很大程度上仅适用于推荐系统(recommendation system)。 例如,通过城市摄像机搜索免费停车位是由慢速准确模型执行的,而汽车碰撞警告与快速不准确模型有关。 提高实时目标检测器的准确性不仅可以将它们用于提示生成推荐系统,还可以用于独立流程管理(stand-alone process management)和减少人工输入。 传统图形处理单元 (GPU) 上的实时目标检测器操作允许以实惠的价格大规模使用。 最精确的现代神经网络无法实时运行,并且需要大量的 GPU 进行大型小型批处理大小的训练。我们通过创建一个在传统 GPU 上实时运行的 CNN 来解决这些问题,为此训练只需要一个常规 GPU。
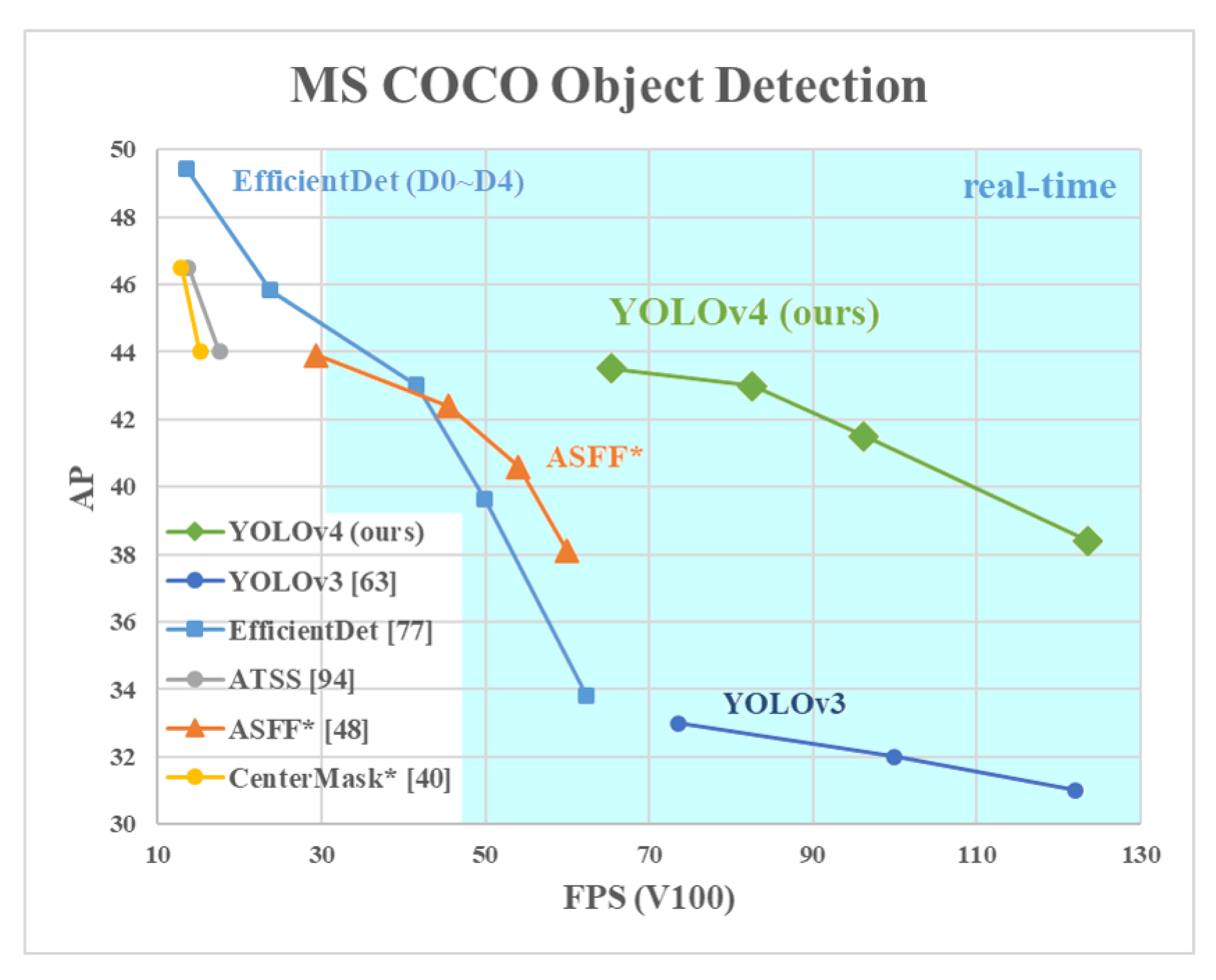
Figure 1: Comparison of the proposed YOLOv4 and other state-of-the-art object detectors. YOLOv4 runs twice faster than EfficientDet with comparable performance. Improves YOLOv3’s AP and FPS by 10% and 12%, respectively.
图1:对YOLOv4和其他最先进的目标检测器进行比较。具有同等的性能情况下,YOLOv4的速度是 EfficientDet 的两倍。并且 YOLOv4 将YOLOv3 的 AP 和 FPS 分别提高了 10% 和 12%。
The main goal of this work is designing a fast operating speed of an object detector in production systems and opti- mization for parallel computations, rather than the low com- putation volume theoretical indicator (BFLOP). We hope that the designed object can be easily trained and used. For example, anyone who uses a conventional GPU to train and test can achieve real-time, high quality, and convincing ob- ject detection results, as the YOLOv4 results shown in Fig- ure 1. Our contributions are summarized as follows:
这项工作的主要目标是设计生产系统中运行速度较快的目标检测器,并优化并行计算,而不是低计算量理论指标 (BFLOP)。我们希望设计的检测器能够轻松训练和使用。例如,使用任何传统 GPU 进行训练和测试的人都可以获得实时、高质量和令人信服的目标检测结果,如图 1 所示的 YOLOv4 结果所示。我们的贡献总结如下:
- 1) We develope an efficient and powerful object detection model. It makes everyone can use a 1080 Ti or 2080 Ti GPU to train a super fast and accurate object detector.
-
1)我们开发了一个高效而强大的对象检测模型。 它使每个人都可以使用 1080 Ti 或 2080 Ti GPU 来训练一个超快速和准确的目标 检测器。
-
2)We verify the influence of state-of-the-art Bag-of- Freebies and Bag-of-Specials methods of object detec- tion during the detector training.
-
2)在检测器训练期间,我们验证了最先进的 Bag-of-Freebies 和 Bag-of-Specials 目标检测方法的影响。
-
3)We modify state-of-the-art methods and make them more effecient and suitable for single GPU training, including CBN [89], PAN [49], SAM [85], etc.
-
3)我们修改了最先进的方法,使其更有效,更适合单 GPU 训练,方法包括 CBN [89]、PAN [49]、SAM [85] 等。
2. Related work 相关工作
2.1. Object detection models 目标检测模型
A modern detector is usually composed of two parts,a backbone which is pre-trained on ImageNet and a head which is used to predict classes and bounding boxes of objects.For those detectors running on GPU platform, their backbone could be VGG [68], ResNet [26], ResNeXt [86], or DenseNet [30]. For those detectors running on CPU platform, their backbone could be SqueezeNet [31], MobileNet [28, 66, 27, 74], or ShuffleNet [97, 53]. As to the head part, it is usually categorized into two kinds, i.e., one-stage object detector and two-stage object detector. The most representative two-stage object detector is the R-CNN [19] series, including fast R-CNN [18], faster R-CNN [64], R-FCN [9], and Libra R-CNN [58]. It is also possible to make a two- stage object detector an anchor-free object detector, such as RepPoints [87]. As for one-stage object detector, the most representative models are YOLO [61, 62, 63], SSD [50], and RetinaNet [45]. In recent years, anchor-free one-stage object detectors are developed. The detectors of this sort are CenterNet [13], CornerNet [37, 38], FCOS [78], etc. Object detectors developed in recent years often insert some layers between backbone and head, and these layers are usually used to collect feature maps from different stages. We can call it the neck of an object detector. Usually, a neck is composed of several bottom-up paths and several topdown paths. Networks equipped with this mechanism include Feature Pyramid Network (FPN) [44], Path Aggregation Network (PAN) [49], BiFPN [77], and NAS-FPN [17].
现代检测器通常由两部分组成,一个是在 ImageNet 上预先训练的骨干网,另一个是用于预测物体的类和边界框的头部。对于在 GPU 平台上运行的检测器,其主干可以是 VGG [68]、ResNet [26]、ResNeXt [86]或DenseNet [30]。对于在 CPU 平台上运行的检测器,其主干可以是SqueezeNet [31], MobileNet [28, 66, 27, 74], 或 ShuffleNet [97, 53].。至于头部部分,通常分为两类 , 即单阶段目标检测器和两阶段目标检测器 。最具代表性的两级目标检测器是R-CNN[19]系列,包括fast R-CNN [18], faster R-CNN [64], R-FCN [9], 和 Libra R-CNN [58] 。也可以使两阶段目标检测器成为无锚目标检测器,如 RepPoints [87]。至于单阶段目标检测器,最具代表性的型号是YOLO[61、62、63]、SSD[50]和RetinaNet[45]。近年来,研制了无锚式单阶段目标检测器。此类检测器有 CenterNet [13]、CornerNet [37、 38]、FCOS [78]等。近年来目标检测器的研发通常是在骨干和头部之间的添加一些层,这些层通常用于收集不同阶段的特征图。我们可以称它为目标检测器的脖子。通常,颈部由几个自下而上的路径和几个自上而下的路径组成。配备此机制的网络包括特征金字塔网络 (FPN) [44]、路径聚合网络 (PAN) [49]、BiFPN [77]和 NAS-FPN [17]。
In addition to the above models, some researchers put their emphasis on directly building a new backbone (DetNet [43], DetNAS [7]) or a new whole model (SpineNet [12], HitDetector [20]) for object detection.
除了上述模型外,一些研究人员还把重点直接放在构建一个新的主干(DetNet [43],DetNAS [7])或新的完整模型(SpineNet [12],HitDetector [20])用于目标检测。
To sum up, an ordinary object detector is composed of several parts:
综上所述,一个普通的目标检测器由如下部分组成:
- Input: Image, Patches, Image Pyramid
- Backbones: VGG16 [68], ResNet-50 [26], SpineNet [12], EfficientNet-B0/B7 [75], CSPResNeXt50 [81], CSPDarknet53 [81]
- Neck:
- Additional blocks: SPP [25], ASPP [5], RFB [47], SAM [85]
- Path-aggregation blocks: FPN [44], PAN [49], NAS-FPN [17], Fully-connected FPN, BiFPN [77], ASFF [48], SFAM [98]
- Heads:
- Dense Prediction (one-stage):
- RPN [64], SSD [50], YOLO [61], RetinaNet [45] (anchor based)
- CornerNet [37], CenterNet [13], MatrixNet [60], FCOS [78] (anchor free)
- Sparse Prediction (two-stage):
- Faster R-CNN [64], R-FCN [9], Mask R-CNN [23] (anchor based)
- RepPoints [87] (anchor free)
- Dense Prediction (one-stage):
2.2. Bag of freebies
Usually, a conventional object detector is trained offline. Therefore, researchers always like to take this advantage and develop better training methods which can make the object detector receive better accuracy without increasing the inference cost. We call these methods that only change the training strategy or only increase the training cost as “bag of freebies.” What is often adopted by object detection methods and meets the definition of bag of freebies is data augmentation. The purpose of data augmentation is to increase the variability of the input images, so that the designed object detection model has higher robustness to the images obtained from different environments. For examples, photometric distortions and geometric distortions are two commonly used data augmentation method and they definitely benefit the object detection task. In dealing with photometric distortion, we adjust the brightness, contrast, hue, saturation, and noise of an image. For geometric distortion, we add random scaling, cropping, flipping, and rotating.
通常,传统的物体检测器是离线训练的。 因此,研究人员总是喜欢利用这一优势,开发更好的训练方法,使目标检测器在不增加推理成本的情况下获得更好的准确性。我们将这些只会改变训练策略或只会增加训练成本的方法称为 “bag of freebies”。目标检测方法经常采用且符合bag of freebies 定义的是数据增强(data augmentation)。数据增强的目的是增加输入图像的可变性(variability),使设计的目标检测模型对不同环境下获得的图像具有更高的鲁棒性。例如,光度失真(photometric distortion)和几何失真(geometric distortion)是两种常用的数据增强方法,它们绝对有利于目标检测任务。在处理光度失真时,我们调整图像的亮度(brightness)、对比度(contrast)、色调(hue)、饱和度(saturation)和噪声(noise)。 对于几何失真,我们添加了随机缩放(random scale)、裁剪(crop)、翻转(flip)和旋转(rotate)。
The data augmentation methods mentioned above are all pixel-wise adjustments, and all original pixel information in the adjusted area is retained. In addition, some researchers engaged in data augmentation put their emphasis on sim- ulating object occlusion issues. They have achieved good results in image classification and object detection. For ex- ample, random erase [100] and CutOut [11] can randomly select the rectangle region in an image and fill in a random or complementary value of zero. As for hide-and-seek [69] and grid mask [6], they randomly or evenly select multiple rectangle regions in an image and replace them to all ze- ros. If similar concepts are applied to feature maps, there are DropOut [71], DropConnect [80], and DropBlock [16] methods. In addition, some researchers have proposed the methods of using multiple images together to perform data augmentation. For example, MixUp [92] uses two images to multiply and superimpose with different coefficient ra- tios, and then adjusts the label with these superimposed ra- tios. As for CutMix [91], it is to cover the cropped image to rectangle region of other images, and adjusts the label according to the size of the mix area. In addition to the above mentioned methods, style transfer GAN [15] is also used for data augmentation, and such usage can effectively reduce the texture bias learned by CNN.
上面提到的数据增强方法都是逐像素(pixel-wise)调整的,并且保留了调整区域内的所有原始像素信息。 此外,一些从事数据增强的研究人员将重点放在模拟对象遮挡(occlusion)问题上。他们在图像分类和目标检测方面取得了很好的效果。 例如,随机擦除[100]和CutOut[11]可以随机选择图像中的矩形区域并填充随机值或互补值零(complementary value of zero)。至于捉迷藏(hide-and-seek) [69] 和网格蒙版(grid mask) [6],它们随机或均匀地选择图像中的多个矩形区域并将它们全替换为零。 如果将类似的概念应用于特征图,则有 DropOut [71]、DropConnect [80] 和 DropBlock [16] 方法。 此外,一些研究人员提出了将多个图像一起使用来进行数据增强的方法。 例如,MixUp [92] 使用两幅图像来使不同的系数比例(coefficient ratio)相乘叠加(superimpose),然后用这些叠加比例调整标签。至于CutMix [91],就是将裁剪后的图像覆盖到其他图像的矩形区域,并根据混合区域的大小调整标签。 除了上述方法外,风格迁移 GAN [15] 也被用于数据增强,这种用法可以有效减少 CNN 学习到的纹理(texture)偏差。
Different from the various approaches proposed above, some other bag of freebies methods are dedicated to solving the problem that the semantic distribution in the dataset may have bias. In dealing with the problem of semantic distribution bias, a very important issue is that there is a problem of data imbalance between different classes, and this problem is often solved by hard negative example mining [72] or online hard example mining [67] in two-stage object detector. But the example mining method is not applicable to one-stage object detector, because this kind of detector belongs to the dense prediction architecture. Therefore Lin et al. [45] proposed focal loss to deal with the problem of data imbalance existing between various classes. Another very important issue is that it is difficult to express the relationship of the degree of association between different categories with the one-hot hard representation. This representation scheme is often used when executing labeling. The label smoothing proposed in [73] is to convert hard label into soft label for training, which can make model more robust. In order to obtain a better soft label, Islam et al. [33] introduced the concept of knowledge distillation to design the label refinement network.
与上面提出的各种方法不同,其他一些bag of freebies方法专门用于解决数据集中语义分布(semantic distribution)可能存在偏差的问题。在处理语义分布偏差问题时,一个非常重要的问题是不同类之间存在数据不平衡(data imbalance)的问题。 这个问题通常通过两阶段目标检测器中的硬反例挖掘(hard negative example mining)[72]或在线硬示例挖掘(online hard example mining)[67]来解决。 但是示例挖掘方法不适用于单阶段目标检测器,因为这种检测器属于密集预测架构。因此 Lin 等人 [45] 提出了focal loss 来处理各个类之间存在的数据不平衡问题。 另一个非常重要的问题是,使用one-hot hard表示很难表达不同类别之间的关联程度的关系。 这种表示方案在进行标注时经常使用。[73]中提出的标签平滑(label smoothing)是将硬标签(hard label)转换为软标签(soft label)进行训练,可以使模型更加鲁棒。 为了获得更好的软标签,Islam等[33]引入了知识蒸馏(knowledge distillation)的概念来设计标签细化网络(label refinement network)。
The last bag of freebies is the objective function of
Bounding Box (BBox) regression. The traditional object
detector usually uses Mean Square Error (MSE) to directly perform regression on the center point coordinates
and height and width of the BBox, i.e., \({x_{center}, y_{center},
w, h}\) , or the upper left point and the lower right point,
i.e., \({x_{top-left}, y_{top-left}, x_{bottom-right}, y_{bottom-right} }\) . As
for anchor-based method, it is to estimate the corresponding offset,
for example
\({x_{center-offset}, y_{center-offset},w_{offset}, h_{offset}}\)
and
\({x_{top-left-offset}, y_{top-left-offset},x_{bottom-right-offset}, y_{bottom-right-offset}}\) .
However, to directly estimate the coordinate values of each point of the
BBox is to treat these points as independent variables, but
in fact does not consider the integrity of the object itself. In
order to make this issue processed better, some researchers
recently proposed IoU loss [90], which puts the coverage of
predicted BBox area and ground truth BBox area into consideration. The IoU loss computing process will trigger the
calculation of the four coordinate points of the BBox by executing IoU with the ground truth, and then connecting the
generated results into a whole code. Because IoU is a scale
invariant representation, it can solve the problem that when
traditional methods calculate the \(l_1\) or \(l_2\) loss of
\({x, y, w,h}\) , the loss will increase with the scale. Recently, some
researchers have continued to improve IoU loss. For example, GIoU loss [65] is to include the shape and orientation
of object in addition to the coverage area. They proposed to
find the smallest area BBox that can simultaneously cover
the predicted BBox and ground truth BBox, and use this BBox as the denominator to replace the denominator originally used in IoU loss. As for DIoU loss [99], it additionally considers the distance of the center of an object, and CIoU loss [99], on the other hand simultaneously considers the
overlapping area, the distance between center points, and the aspect ratio. CIoU can achieve better convergence speed and accuracy on the BBox regression problem.
最后一些 bag of freebies 是边界框 (BBox) 回归的目标函数。 传统的目标检测器通常使用均方误差(MSE)直接对BBox的中心点坐标和高度和宽度进行回归,即 \({x_{center}, y_{center},w, h}\),或左上点和右下点,即 \({x_{top-left}, y_{top-left}, x_{bottom-right}, y_{bottom-right} }\) 。对于anchor-based方法,就是估计对应的offset,例如 \({x_{center-offset}, y_{center-offset},w_{offset}, h_{offset}}\) 和 \({x_{top-left-offset}, y_{top-left-offset},x_{bottom-right-offset}, y_{bottom-right-offset}}\) 。但是,直接估计BBox每个点的坐标值,就是把这些点当成自变量(independent variable),实际上并没有考虑对象本身的完整性。 为了更好地处理这个问题,最近有研究人员提出了 IoU loss [90],它考虑了预测 BBox 区域和真实BBox 区域的覆盖范围。IoU 损失计算过程通过使用真实值计算IoU 来触发BBox 四个坐标点的计算,然后将生成的结果连接成一个完整的代码。由于IoU是比例不变的表示,可以解决传统方法计算 \({x,y,w,h}\) 的 \(l_1\) 或 \(l_2\) 损失时,损失会随着比例增加的问题。最近,一些研究人员继续改进 IoU 损失。例如,GIoU loss[65]除了覆盖区域外,还包括物体的形状和方向(orientation)。他们提出寻找可同时覆盖预测BBox和真实BBox的最小面积BBox,并用这个BBox作为分母(denominator)来代替原来在IoU loss中使用的分母。至于DIoU loss [99],它额外考虑了物体中心的距离,而CIoU loss [99],另一方面同时考虑了重叠区域、中心点之间的距离和宽高比。CIoU 在 BBox 回归问题上可以达到更好的收敛速度和精度。
2.3. Bag of specials
For those plugin modules and post-processing methods that only increase the inference cost by a small amount but can significantly improve the accuracy of object detection, we call them “bag of specials”. Generally speaking, these plugin modules are for enhancing certain attributes in a model, such as enlarging receptive field, introducing attention mechanism, or strengthening feature integration capability, etc., and post-processing is a method for screening model prediction results.
对于那些只增加少量推理成本但可以显着提高目标检测精度的插件模块(plugin module)和后处理(post-processing)方法,我们称之为“bag of specials”。 一般来说,这些插件模块是为了增强模型中的某些属性(attribute),比如扩大感受野(receptive field)、引入注意力机制(attention mechanism)、或者加强特征整合(integration)能力等,后处理是一种筛选(screen)模型预测结果的方法。
Common modules that can be used to enhance receptive field are SPP [25], ASPP [5], and RFB [47]. The SPP module was originated from Spatial Pyramid Matching (SPM) [39], and SPMs original method was to split feature map into several d × d equal blocks, where d can be \({1, 2, 3, ...}\), thus forming spatial pyramid, and then extracting bag-of-word features. SPP integrates SPM into CNN and use max-pooling operation instead of bag-of-word operation. Since the SPP module proposed by He et al. [25] will output one dimensional feature vector, it is infeasible to be applied in Fully Convolutional Network (FCN). Thus in the design of YOLOv3 [63], Redmon and Farhadi improve SPP module to the concatenation of max-pooling outputs with kernel size \(k × k\) , where \(k = {1, 5, 9, 13}\) , and stride equals to 1. Under this design, a relatively large k × k maxpooling effectively increase the receptive field of backbone feature. After adding the improved version of SPP module, YOLOv3-608 upgrades AP50 by 2.7% on the MS COCO object detection task at the cost of 0.5% extra computation. The difference in operation between ASPP [5] module and improved SPP module is mainly from the original k×k kernel size, max-pooling of stride equals to 1 to several \(3 × 3\) kernel size, dilated ratio equals to k, and stride equals to 1 in dilated convolution operation. RFB module is to use several dilated convolutions of k×k kernel, dilated ratio equals to k, and stride equals to 1 to obtain a more comprehensive spatial coverage than ASPP . RFB [47] only costs 7% extra inference time to increase the AP50 of SSD on MS COCO by 5.7%.
可用于增强感受野的常见模块有 SPP [25]、ASPP [5] 和 RFB [47]。SPP模块起源于Spatial Pyramid Matching(SPM)[39],SPM的原始方法是将特征图分割成几个 \(d × d\) 相等的块,其中 \(d\) 可以是 \({1, 2, 3, ...}\) ,因此形成空间金字塔,然后提取词袋(bag-of-word)特征。SPP 将 SPM 集成到 CNN 中并使用最大池化操作而不是词袋操作。由于He等人[25]提出的SPP模块会输出一维特征向量,因此不适用于全卷积网络(FCN)。因此,在 YOLOv3 [63] 的设计中,Redmon 和 Farhadi 将 SPP 模块改进为 内核大小为 \(k × k\) 的最大池化输出的串联,其中 \(k = {1, 5, 9, 13}\) ,步幅等于 1。 在这种设计下,相对较大的 \(k × k\) 最大池化有效地增加了主干(backbone)特征的感受野。添加改进版SPP模块后,YOLOv3-608在MS COCO物体检测任务上以0.5%的额外计算为代价将AP50提升了2.7%。ASPP [5] 模块和改进的 SPP 模块在操作上的区别主要是原始的 \(k×k\) 核大小,最大池化的步幅等于1 到几个 \(3×3\) 核大小,扩张比(dilated ratio)等于 k,在扩张卷积(dilated convolution)操作中步幅等于 1。RFB模块是使用几个k×k核的扩张卷积,扩张比等于k,步幅等于1,以获得比ASPP更全面的空间覆盖。RFB [47] 仅花费 7% 的额外推理时间即可对 MS COCO 上 SSD 的 AP50 提高 5.7%。
The attention module that is often used in object detection is mainly divided into channel-wise attention and point-wise attention, and the representatives of these two attention models are Squeeze-and-Excitation (SE) [29] and Spatial Attention Module (SAM) [85], respectively. Although SE module can improve the power of ResNet50 in the ImageNet image classification task 1% top-1 accuracy at the cost of only increasing the computational effort by 2%, but on a GPU usually it will increase the inference time by about 10%, so it is more appropriate to be used in mobile devices. But for SAM, it only needs to pay 0.1% extra calculation and it can improve ResNet50-SE 0.5% top-1 accuracy on the ImageNet image classification task. Best of all, it does not affect the speed of inference on the GPU at all.
目标检测中经常使用的注意力模块(attention module)主要分为逐通道注意力(channel-wise attention)和逐点注意力(point-wise attention),这两种注意力模型的代表分别是Squeeze-and-Excitation(SE)[29]和Spatial Attention Module(SAM)[85]。虽然 SE 模块可以将 ResNet50 在 ImageNet 图像分类任务中的能力提高 1% \(top-1\) 准确率,代价是只增加 2% 的计算量,但在 GPU 上通常会增加大约 10% 的推理时间, 所以更适合用在移动设备上。但对于 SAM 来说,它只需要额外付出 0.1% 的计算,就可以将 ResNet50-SE 在 ImageNet 图像分类任务上的 \(top-1\) 准确率提高 0.5%。 最重要的是,它不会影响 GPU 上的推理速度。
In terms of feature integration, the early practice is to use skip connection [51] or hyper-column [22] to integrate low- level physical feature to high-level semantic feature. Since multi-scale prediction methods such as FPN have become popular, many lightweight modules that integrate different feature pyramid have been proposed. The modules of this sort include SFAM [98], ASFF [48], and BiFPN [77]. The main idea of SFAM is to use SE module to execute channel- wise level re-weighting on multi-scale concatenated feature maps. As for ASFF, it uses softmax as point-wise level re- weighting and then adds feature maps of different scales. In BiFPN, the multi-input weighted residual connections is proposed to execute scale-wise level re-weighting, and then add feature maps of different scales.
在特征整合(feature integration)方面,早期的做法是使用跳过连接(skip connection)[51]或超列(hyper-column)[22]将低级物理特征整合到高级语义特征(semantic feature)。 随着FPN等多比例(multi-scale)预测方法的流行,许多集成不同特征金字塔的轻量级模块被提出。 这类模块包括 SFAM [98]、ASFF [48] 和 BiFPN [77]。 SFAM 的主要思想是使用 SE 模块在多比例级联(multi-scale concatenated)特征图上执行逐通道水平的重新加权(channel-wise level re-weighting)。 至于ASFF,它使用softmax作为逐点级重加权(point-wise level re-weighting),然后添加不同比例的特征图。 在 BiFPN 中,提出了使用多输入加权残差连接(multi-input weighted residual connections)来执行按尺度级别重新加权(scale-wise level re-weighting),然后添加不同尺度的特征图。
In the research of deep learning, some people put their focus on searching for good activation function. A good activation function can make the gradient more efficiently propagated, and at the same time it will not cause too much extra computational cost. In 2010, Nair and Hin- ton [56] propose ReLU to substantially solve the gradient vanish problem which is frequently encountered in tradi- tional tanh and sigmoid activation function. Subsequently, LReLU [54], PReLU [24], ReLU6 [28], Scaled Exponential Linear Unit (SELU) [35], Swish [59], hard-Swish [27], and Mish [55], etc., which are also used to solve the gradient vanish problem, have been proposed. The main purpose of LReLU and PReLU is to solve the problem that the gradi- ent of ReLU is zero when the output is less than zero. As for ReLU6 and hard-Swish, they are specially designed for quantization networks. For self-normalizing a neural net- work, the SELU activation function is proposed to satisfy the goal. One thing to be noted is that both Swish and Mish are continuously differentiable activation function.
在深度学习的研究中,有人把重点放在寻找好的激活函数上。一个好的激活函数可以让梯度更有效地传播,同时不会造成太多额外的计算成本。2010 年,Nair 和 Hinton [56] 提出 ReLU 来实质性地解决传统 tanh 和 sigmoid 激活函数中经常遇到的梯度消失(gradient vanish)问题。随后,LReLU [54]、PReLU [24]、ReLU6 [28]、Scaled Exponential Linear Unit (SELU) [35]、Swish [59]、hard-Swish [27] 和 Mish [55] 等被提出,也用于解决梯度消失问题。LReLU和PReLU的主要目的是解决输出小于零时ReLU梯度为零的问题。至于 ReLU6 和 hard-Swish,它们是专门为量化(quantization)网络设计的。为了自归一化(self-normalize)神经网络,SELU 激活函数被提出以实现该目标。需要注意的一件事是 Swish 和 Mish 都是连续可微(continuously differentiable)的激活函数。
The post-processing method commonly used in deep- learning-based object detection is NMS, which can be used to filter those BBoxes that badly predict the same ob- ject, and only retain the candidate BBoxes with higher re- sponse. The way NMS tries to improve is consistent with the method of optimizing an objective function. The orig- inal method proposed by NMS does not consider the con- text information, so Girshick et al. [19] added classification confidence score in R-CNN as a reference, and according to the order of confidence score, greedy NMS was performed in the order of high score to low score. As for soft NMS [1], it considers the problem that the occlusion of an object may cause the degradation of confidence score in greedy NMS with IoU score. The DIoU NMS [99] developers way of thinking is to add the information of the center point dis- tance to the BBox screening process on the basis of soft NMS. It is worth mentioning that, since none of above post- processing methods directly refer to the captured image fea- tures, post-processing is no longer required in the subse- quent development of an anchor-free method.
基于深度学习的物体检测常用的后处理(post-processing)方法是NMS,它可以用来过滤那些对同一物体预测不好的BBox,只保留响应较高的候选BBox。NMS 尝试改进的方式与优化目标函数的方法一致。 NMS 提出的原始方法没有考虑上下文(context)信息,因此 Girshick 等人 [19] 在 R-CNN 中添加了分类置信度(classification confidence score)分数作为参考,并按照置信度得分的顺序,从高分到低分的顺序进行贪婪(greedy)NMS。对于 soft NMS [1],它考虑了在具有 IoU 分数的 greedy NMS 中对象的遮挡(occlusion)可能导致置信度下降的问题。 DIoU NMS [99] 开发者的思路是在软 NMS 的基础上,在 BBox 筛选(screen)过程中加入中心点距离信息。 值得一提的是,由于上述后处理方法都没有直接参考捕获的图像特征,因此在后续开发anchor-free方法时不再需要进行后处理。
3. Methodology 方法论
The basic aim is fast operating speed of neural network, in production systems and optimization for parallel compu- tations, rather than the low computation volume theoreti- cal indicator (BFLOP). We present two options of real-time neural networks:
基本目标是神经网络在生产系统中的快速运行和并行计算(parallel computation)的优化,而不是低计算量理论指标(low computation volume theoretical indicator)(BFLOP)。 我们提供了两种实时神经网络选项:
-
For GPU we use a small number of groups (1 - 8) in convolutional layers: CSPResNeXt50 / CSPDarknet53
-
对于 GPU,我们在卷积层中使用少量组 (1 - 8):CSPResNeXt50 / CSPDarknet53
-
For VPU - we use grouped-convolution, but we refrain from using Squeeze-and-excitement (SE) blocks specifically this includes the following models: EfficientNet-lite / MixNet [76] / GhostNet [21] / Mo-bileNetV3
- 对于 VPU - 我们使用分组卷积,但我们避免使用 Squeeze-and-excitement (SE) 块 , - 具体包括模型:EfficientNet-lite / MixNet [76] / GhostNet [21] / MobileNetV3
3.1. Selection of architecture 架构选择
Our objective is to find the optimal balance among the in- put network resolution, the convolutional layer number, the parameter number \((filter size^2 * filters * channel / groups)\) , and the number of layer outputs (filters). For instance, our numerous studies demonstrate that the CSPResNext50 is considerably better compared to CSPDarknet53 in terms of object classification on the ILSVRC2012 (ImageNet) dataset [10]. However, conversely, the CSPDarknet53 is better compared to CSPResNext50 in terms of detecting ob- jects on the MS COCO dataset [46].
我们的目标是在输入网络分辨率、卷积层数、参数数量 \((filter size^2 * filters * channel / groups)\) 和层输出数(过滤器)之间找到最佳平衡。 例如,我们的大量研究表明,在 ILSVRC2012 (ImageNet) 数据集 [10] 上的对象分类方面,CSPResNext50 与 CSPDarknet53 相比要好得多。 然而,相反,在 MS COCO 数据集上进行目标检测,CSPDarknet53 比 CSPResNext50 更好 [46]。
The next objective is to select additional blocks for increasing the receptive field and the best method of parameter aggregation from different backbone levels for different detector levels: e.g. FPN, PAN, ASFF, BiFPN.
下一个目标是选择额外的块来增加感受野,以及从不同的主干级别为不同的检测器级别选择参数聚合(parameter aggregation)的最佳方法:例如 FPN、PAN、ASFF、BiFPN。
A reference model which is optimal for classification is not always optimal for a detector. In contrast to the classifier, the detector requires the following:
对于分类而言最佳的参考模型对于检测器而言并不总是最佳的。 与分类器相比,检测器需要以下内容:
-
Higher input network size (resolution) – for detecting multiple small-sized objects
-
更高的输入网络尺寸(分辨率)—— 用于检测多个小尺寸物体
-
More layers – for a higher receptive field to cover the increased size of input network
-
更多层——用于更高的感受野以覆盖增加的输入网络大小
-
More parameters – for greater capacity of a model to detect multiple objects of different sizes in a single im- age
-
更多参数——使模型有更大的能力在单个图像中检测多个不同大小的对象

\(\text { 表 1: 用于图像分类的神经网络参数。 }\)
Hypothetically speaking, we can assume that a model with a larger receptive field size (with a larger number of convolutional layers \(3 × 3\) ) and a larger number of parameters should be selected as the backbone. Table 1 shows the information of CSPResNeXt50, CSPDarknet53, and EfficientNet B3. The CSPResNext50 contains only 16 convolutional layers \(3 × 3\) , a \(425 × 425\) receptive field and 20.6 M parameters, while CSPDarknet53 contains 29 convolu- tional layers \(3 × 3\) , a \(725 × 725\) receptive field and 27.6 M parameters. This theoretical justification, together with our numerous experiments, show that CSPDarknet53 neural network is the optimal model of the two as the backbone for a detector.
假设地说,我们可以假设应该选择具有更大感受野大小(具有更多卷积层 3 × 3)和更多参数的模型作为主干。 表 1 显示了 CSPResNeXt50、CSPDarknet53 和 EfficientNet B3 的信息。 CSPResNext50 仅包含 16 个 3 × 3 卷积层、425 × 425 感受野和 20.6 M 参数,而 CSPDarknet53 包含 29 个卷积层 3 × 3、725 × 725 感受野和 27.6 M 参数。 这个理论证明,加上我们的大量实验,表明 CSPDarknet53 神经网络是两者的最佳模型,作为检测器的主干。
The influence of the receptive field with different sizes is summarized as follows:
不同大小的感受野的影响总结如下:
- Up to the object size - allows viewing the entire object
- 最多到对象大小 – 允许查看整个对象
- Up to network size - allows viewing the context around the object
- 最多网络大小 – 允许查看对象周围的上下文
- Exceeding the network size - increases the number of connections between the image point and the final activation
- 超过网络大小 – 增加图像点和最终激活之间的连接数
We add the SPP block over the CSPDarknet53, since it significantly increases the receptive field, separates out the most significant context features and causes almost no reduction of the network operation speed. We use PANet as the method of parameter aggregation from different backbone levels for different detector levels, instead of the FPN used in YOLOv3.
我们在 CSPDarknet53 上添加了 SPP 块,因为它显着增加了感受野,分离出最重要的上下文特征,并且几乎不会降低网络运行速度。 我们使用 PANet 作为来自不同主干级别的对不同检测器级别的参数聚合方法,而不是 YOLOv3 中使用的 FPN。
Finally, we choose CSPDarknet53 backbone, SPP additional module, PANet path-aggregation neck, and YOLOv3 (anchor based) head as the architecture of YOLOv4.
最后,我们选择 CSPDarknet53 主干、SPP 附加模块、PANet 路径聚合颈部和 YOLOv3((anchor based)头部作为 YOLOv4 的架构。
n the future we plan to expand significantly the content of Bag of Freebies (BoF) for the detector, which theoreti- cally can address some problems and increase the detector accuracy, and sequentially check the influence of each fea- ture in an experimental fashion.
未来我们计划大力扩展检测器的Bag of Freebies (BoF) 内容,理论上可以解决一些问题并提高检测器的准确性,并以实验方式依次检查每个特征的影响。
We do not use Cross-GPU Batch Normalization (CGBN or SyncBN) or expensive specialized devices. This al- lows anyone to reproduce our state-of-the-art outcomes on a conventional graphic processor e.g. GTX 1080Ti or RTX 2080Ti.
我们不使用跨 GPU(Cross-GPU)批量归一化(CGBN 或 SyncBN)或昂贵的专用设备。 这允许任何人在传统图形处理器上重现我们最先进的结果,例如 GTX 1080Ti 或 RTX 2080Ti。
3.2. Selection of BoF and BoS
For improving the object detection training, a CNN usu- ally uses the following:
为了改进目标检测训练,CNN 通常使用以下内容:
- Activations: ReLU, leaky-ReLU, parametric-ReLU, ReLU6, SELU, Swish, or Mish
- 激活:ReLU、leaky-ReLU、参数化 ReLU(parametric-ReLU)、ReLU6、SELU、Swish 或 Mish
- Bounding box regression loss: MSE, IoU, GIoU,CIoU, DIoU
- 边界框回归损失:MSE、IoU、GIoU、CIoU、DIoU
- Data augmentation: CutOut, MixUp, CutMix
- 数据增强:CutOut、MixUp、CutMix
- Regularization method: DropOut, DropPath [36],Spatial DropOut [79], or DropBlock
- 正则化方法:DropOut、DropPath [36]、Spatial DropOut [79] 或 DropBlock
- Normalization of the network activations by their mean and variance: Batch Normalization (BN) [32], Cross-GPU Batch Normalization (CGBN or SyncBN)[93], Filter Response Normalization (FRN) [70], or Cross-Iteration Batch Normalization (CBN) [89]
- 通过均值和方差对网络激活进行归一化:批归一化 (BN) [32]、Cross-GPU 批归一化(CGBN 或 SyncBN)[93]、滤波器响应(Filter Response)归一化 (FRN) [70] 或交叉迭代(Cross-Iteration)批归一化 (CBN) [89]
- Skip-connections: Residual connections, Weighted residual connections, Multi-input weighted residual connections, or Cross stage partial connections (CSP)
- 跳过连接(Skip-connections):残差连接(Residual connection)、加权残差连接、多输入(Multi-input)加权残差连接或跨阶段部分连接(Cross stage partial connections) (CSP)
As for training activation function, since PReLU and SELU are more difficult to train, and ReLU6 is specifically designed for quantization network, we therefore remove the above activation functions from the candidate list. In the method of reqularization, the people who published Drop- Block have compared their method with other methods in detail, and their regularization method has won a lot. There- fore, we did not hesitate to choose DropBlock as our reg- ularization method. As for the selection of normalization method, since we focus on a training strategy that uses only one GPU, syncBN is not considered.
至于训练激活函数,由于 PReLU 和 SELU 更难训练,而 ReLU6 是专门为量化(quantization)网络设计的,因此我们从候选列表中删除了上述激活函数。 在正则化的方法上,发表Drop-Block的人详细对比了他们的方法和其他方法,他们的正则化方法赢得了很多。 因此,我们毫不犹豫地选择 DropBlock 作为我们的正则化方法。 至于归一化方法的选择,由于我们专注于仅使用一个 GPU 的训练策略,因此没有考虑 syncBN。
3.3. Additional improvements
In order to make the designed detector more suitable for training on single GPU, we made additional design and im- provement as follows:
为了使所设计的检测器更适合在单一GPU上训练,我们做了如下额外的设计和改进:
- We introduce a new method of data augmentation Mosaic, and Self-Adversarial Training (SA T)
- 我们引入了数据增强马赛克(Mosaic)和自我对抗训练 (SAT) 的新方法
- We select optimal hyper-parameters while applying genetic algorithms
- 我们在应用遗传算法(genetic algorithm)的同时选择最佳超参数
- We modify some exsiting methods to make our design suitble for efficient training and detection - modified SAM, modified PAN, and Cross mini-Batch Normalization (CmBN)
- 我们修改了一些现有的方法,使我们的设计适合高效的训练和检测——修改的 SAM、修改的 PAN 和交叉小批量归一化 (CmBN)
Mosaic represents a new data augmentation method that mixes 4 training images. Thus 4 different contexts are mixed, while CutMix mixes only 2 input images. This al- lows detection of objects outside their normal context. In addition, batch normalization calculates activation statistics from 4 different images on each layer. This significantly reduces the need for a large mini-batch size.
Mosaic 代表了一种新的数据增强方法,它混合了 4 个训练图像。 因此混合了 4 个不同的上下文,而 CutMix 仅混合了 2 个输入图像。 这允许检测正常上下文之外的对象。 此外,批量归一化计算每层 4 个不同图像的激活统计数据。 这显着减少了对大尺寸 mini-batch 的需求。

Figure 3: Mosaic represents a new method of data augmentation.
图3:马赛克表示一种数据增强的新方法。
Self-Adversarial Training (SAT) also represents a new data augmentation technique that operates in 2 forward backward stages. In the 1st stage the neural network alters the original image instead of the network weights. In this way the neural network executes an adversarial attack on it- self, altering the original image to create the deception that there is no desired object on the image. In the 2nd stage, the neural network is trained to detect an object on this modified image in the normal way.
自我对抗训练 (SAT) 也代表了一种新的数据增强技术,它在 2 个前向和后向阶段中运行。 在第一阶段,神经网络改变原始图像而不是网络权重。 通过这种方式,神经网络对自身执行对抗性攻击,改变原始图像 以制造图像上没有所需对象的欺骗(deception)。 在第二阶段,训练神经网络以正常方式检测此修改图像上的对象。
Figure 4: Cross mini-Batch Normalization.
图 4:交叉小批量归一化。
CmBN represents a CBN modified version, as shown in Figure 4, defined as Cross mini-Batch Normalization (CmBN). This collects statistics only between mini-batches within a single batch.
CmBN 表示 CBN 修改版本,如图 4 所示,定义为交叉小批量归一化 (CmBN)。 这仅在单个批次内的小批次之间收集统计信息。
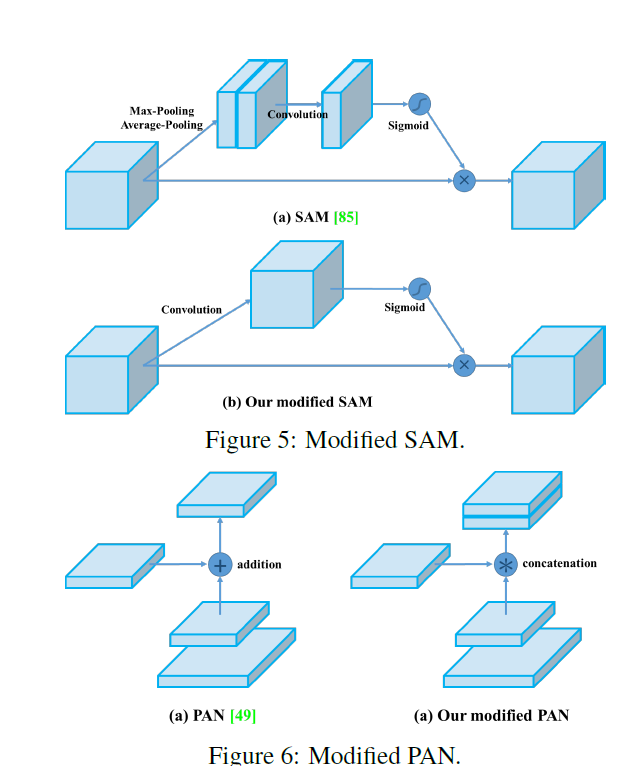
We modify SAM from spatial-wise attention to point- wise attention, and replace shortcut connection of PAN to concatenation, as shown in Figure 5 and Figure 6, respec- tively. 我们将 SAM 从按空间注意(spatial-wise attention)修改为逐点注意(point-wise attention),并将 PAN 的快捷连接(shortcut connection)替换为串联(concatenation),分别如图 5 和图 6 所示。
3.4. YOLOv4
In this section, we shall elaborate the details of YOLOv4.
在本节中,我们将详细阐述YOLOv4的细节。
YOLOv4 consists of:
YOLOv4 包括:
- Backbone: CSPDarknet53 [81]
- Neck: SPP [25], PAN [49]
- Head: YOLOv3 [63]
YOLO v4 uses:
YOLO v4 使用:
- Bag of Freebies (BoF) for backbone: CutMix and Mosaic data augmentation, DropBlock regularization, Class label smoothing
- 骨干的BoF:CutMix 和 Mosaic 数据增强、DropBlock 正则化、类标签平滑(Class label smoothing)
- Bag of Specials (BoS) for backbone: Mish activation, Cross-stage partial connections (CSP), Multiinput weighted residual connections (MiWRC)
- 骨干的BoS:Mish 激活、跨阶段部分连接 (CSP)、多输入加权残差连接 (MiWRC)
- Bag of Freebies (BoF) for detector: CIoU-loss, CmBN, DropBlock regularization, Mosaic data augmentation, Self-Adversarial Training, Eliminate grid sensitivity, Using multiple anchors for a single ground truth, Cosine annealing scheduler [52], Optimal hyperparameters, Random training shapes
- 检测器的BoF:CIoU-loss、CmBN、DropBlock 正则化、Mosaic 数据增强、自我对抗训练(SAT)、消除网格敏感性(Eliminate grid sensitivity)、使用多个锚点(multiple anchors)获取单个真实值、余弦退火调度程序(Cosine annealing scheduler) [52]、最优超参数,随机训练形状
- Bag of Specials (BoS) for detector: Mish activation, SPP-block, SAM-block, PAN path-aggregation block,DIoU-NMS
- 用于检测器的特有包 (BoS): 误区激活、 SPP 块、 SAM 块、 PAN 路径聚合块、 DIoU-NMS
4. Experiments 实验
We test the influence of different training improvement techniques on accuracy of the classifier on ImageNet (ILSVRC 2012 val) dataset, and then on the accuracy of the detector on MS COCO (test-dev 2017) dataset.
我们在 ImageNet (ILSVRC 2012 val) 数据集上测试了不同训练改进技术对分类器准确性的影响,然后在 MS COCO (test-dev 2017) 数据集上测试了检测器的准确性。
4.1. Experimental setup 实验设置
In ImageNet image classification experiments, the default hyper-parameters are as follows: the training steps is 8,000,000; the batch size and the mini-batch size are 128 and 32, respectively; the polynomial decay learning rate scheduling strategy is adopted with initial learning rate 0.1; the warm-up steps is 1000; the momentum and weight decay are respectively set as 0.9 and 0.005. All of our BoS experiments use the same hyper-parameter as the default setting, and in the BoF experiments, we add an additional 50% training steps. In the BoF experiments, we verify MixUp, CutMix, Mosaic, Bluring data augmentation, and label smoothing regularization methods. In the BoS experiments, we compared the effects of LReLU, Swish, and Mish activation function. All experiments are trained with a 1080 Ti or 2080 Ti GPU.
在 ImageNet 图像分类实验中,默认超参数如下:训练步数为 8,000,000; 大批量和小批量大小分别为 128 和 32; 采用多项式衰减学习率调度策略(polynomial decay learning rate scheduling strategy),初始学习率0.1; 预热(warm-up)步数为1000; 动量衰减和权重衰减分别设置为 0.9 和 0.005。我们所有的 BoS 实验都使用与默认设置相同的超参数,并且在 BoF 实验中,我们添加了额外的 50% 训练步数。 在 BoF 实验中,我们验证了 MixUp、CutMix、Mosaic、Bluring 数据增强和标签平滑正则化(label smoothing regularization)方法。 在 BoS 实验中,我们比较了 LReLU、Swish 和 Mish 激活函数的效果。 所有实验均使用 1080 Ti 或 2080 Ti GPU 进行训练。
In MS COCO object detection experiments, the default hyper-parameters are as follows: the training steps is 500,500; the step decay learning rate scheduling strategy is adopted with initial learning rate 0.01 and multiply with a factor 0.1 at the 400,000 steps and the 450,000 steps, respectively; The momentum and weight decay are respec- tively set as 0.9 and 0.0005. All architectures use a single GPU to execute multi-scale training in the batch size of 64 while mini-batch size is 8 or 4 depend on the architectures and GPU memory limitation. Except for us- ing genetic algorithm for hyper-parameter search experiments, all other experiments use default setting. Genetic algorithm used YOLOv3-SPP to train with GIoU loss and search 300 epochs for min-val 5k sets. We adopt searched learning rate 0.00261, momentum 0.949, IoU threshold for assigning ground truth 0.213, and loss normalizer 0.07 for genetic algorithm experiments. We have verified a large number of BoF, including grid sensitivity elimination, mosaic data augmentation, IoU threshold, genetic algorithm, class label smoothing, cross mini-batch normalization, self-adversarial training, cosine annealing scheduler, dynamic mini-batch size, DropBlock, Optimized Anchors, different kind of IoU losses. We also conduct experiments on various BoS, including Mish, SPP, SAM, RFB, BiFPN, and Gaus-sian YOLO [8]. For all experiments, we only use one GPU for training, so techniques such as syncBN that optimizes multiple GPUs are not used.
在 MS COCO 数据集上目标检测实验中,默认超参数如下:训练步数为 500,500; 采用步长衰减学习率调度策略(step decay learning rate scheduling strategy),初始学习率0.01,分别在40万步和45万步乘以因子0.1; 动量和权重衰减分别设置为 0.9 和 0.0005。所有架构(architecture)都使用单个 GPU 以 64 的批量大小执行多比例(multi-scale)训练,而小批量大小为 8 或 4,具体取决于架构和 GPU 内存限制。 除了使用遗传算法进行超参数搜索实验外,其他所有实验均使用默认设置。 遗传算法使用 YOLOv3-SPP 训练 GIoU损失并搜索 300 个 epoch 以获取min-val 5k 集。 我们采用搜索学习率 0.00261,动量 0.949,分配真实值的 IoU 阈值 0.213,遗传算法实验的损失归一化器 0.07。 我们已经验证了大量的 BoF,包括网格敏感性消除(grid sensitivity elimination)、马赛克数据增强、IoU 阈值、遗传算法、类标签平滑、交叉小批量归一化 (CmBN)、自对抗训练、余弦退火调度器、动态小批量大小、DropBlock , 优化的锚点(Optimized Anchor),不同种类的 IoU 损失。 我们还对各种 BoS 进行了实验,包括 Mish、SPP、SAM、RFB、BiFPN 和Gaussian YOLO [8]。 对于所有实验,我们只使用一个 GPU 进行训练,因此没有使用优化多个 GPU 的同步BN(syncBN) 等技术。
4.2. Influence of different features on Classifier 不同特征对分类器训练的影响
First, we study the influence of different features on classifier training; specifically, the influence of Class la- bel smoothing, the influence of different data augmentation techniques, bilateral blurring, MixUp, CutMix and Mosaic, as shown in Fugure 7, and the influence of different activa- tions, such as Leaky-ReLU (by default), Swish, and Mish.
首先,我们研究了不同特征对分类器训练的影响; 具体来说,Class label smoothing的影响,不同数据增强技术的影响,双边模糊(bilateral blurring),MixUp,CutMix和Mosaic,如Fugure 7所示,以及不同激活的影响,例如Leaky-ReLU(默认),Swish ,和Mish。

Figure 7: V arious method of data augmentation.
图7:各种数据增强方法。
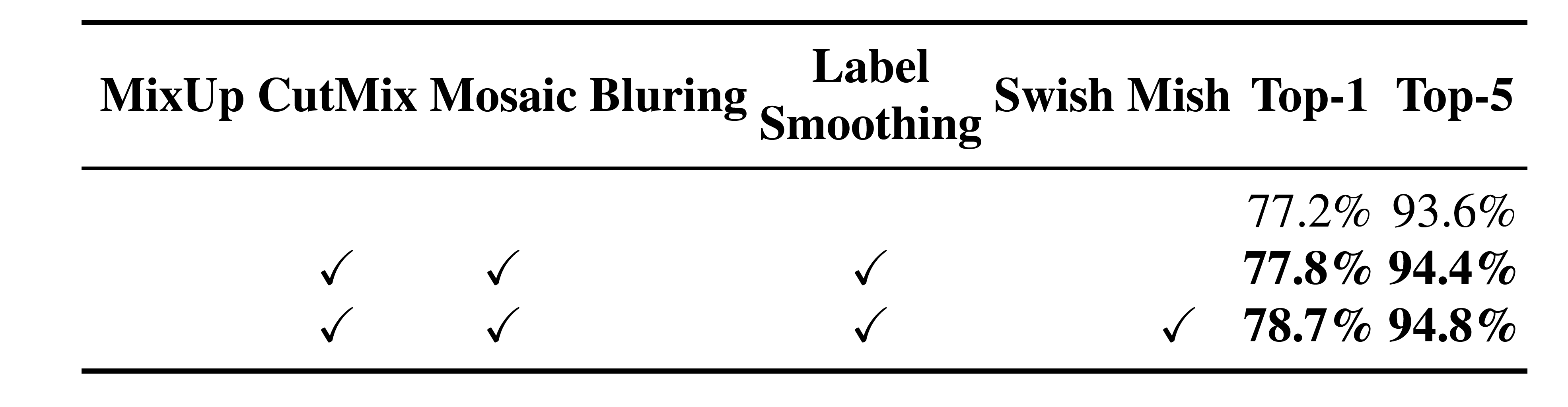
In our experiments, as illustrated in Table 2, the classifier’s accuracy is improved by introducing the features such as: CutMix and Mosaic data augmentation, Class label smoothing, and Mish activation. As a result, our BoF-backbone (Bag of Freebies) for classifier training includes the following: CutMix and Mosaic data augmentation and Class label smoothing. In addition we use Mish activation as a complementary option, as shown in Table 2 and Table
在我们的实验中,如表 2 所示,通过引入以下特征来提高分类器的准确性:CutMix 和 Mosaic 数据增强、类标签平滑和 Mish 激活。 因此,我们用于分类器训练的 BoF-backbone(Bag of Freebies)包括以下内容:CutMix 和 Mosaic 数据增强以及类标签平滑。 此外,我们使用 Mish 激活作为补充选项(complementary option),如表 2 和表 3 所示。
Table 2: Influence of BoF and Mish on the CSPResNeXt-50 classifier accuracy.
表2:BoF和Mish对CSPResNeXt-50分类准确率的影响。

Table 3: Influence of BoF and Mish on the CSPDarknet-53 classifier accuracy.
表3:BoF和Mish对CSPDarknet-53分类准确率的影响。
4.3. Influence of different features on Detector
Further study concerns the influence of different Bag-of-Freebies (BoF-detector) on the detector training accuracy, as shown in Table 4. We significantly expand the BoF list through studying different features that increase the detector accuracy without affecting FPS:
进一步的研究涉及不同的免费袋(BOF探测器)对探测器训练精度的影响,如表4所示。我们通过研究在不影响FPS的情况下提高探测器精度的不同特性,显著扩展了BOF列表:
- S: Eliminate grid sensitivity the equation \(b_x = σ(t_x )+ c_x , b_y = σ(t_y )+c_y\) , where \(c_x\) and \(c_y\) are always whole numbers, is used in YOLOv3 for evaluating the object coordinates, therefore, extremely high \(t_x\) absolute values are required for the \(b_x\) value approaching the \(c_x \ or \ c_{ x} + 1\) values. We solve this problem through multiplying the sigmoid by a factor exceeding 1.0, so eliminating the effect of grid on which the object is undetectable.
-
S: 消除网格灵敏度方程 \(b_x = σ(t_x )+ c_x , b_y = σ(t_y )+c_y\) , 其中 \(c_x\) 和 \(c_y\) 始终为整数, 在 YOLOv3 中使用用于评估目标坐标, 因此,接近 \(c_x \ or \ c_{ x} + 1\) 值的 \(b_x\) 值需要极高的 \(t_x\) 绝对值。我们通过将 sigmoid 乘以超过 1.0 的因子来解决此问题,从而消除了对象无法检测到的网格的影响。
-
M: Mosaic data augmentation – using the 4-image mosaic during training instead of single image
- M:马赛克数据扩增 – 在训练期间使用 4 图像镶嵌,而不是单个图像
- IT: IoU threshold – using multiple anchors for a single ground truth IoU (truth, anchor) > IoU-threshold
- IT:IoU 阈值 – 使用多个锚点进行单个接地真相 IoU(真、锚)和 IoU 阈值 |
- GA: Genetic algorithms – using genetic algorithms for selecting the optimal hyperparameters during network training on the first 10% of time periods
- GA:遗传算法 – 在前 10% 的时间段的网络训练期间使用遗传算法选择最佳超参数*
- LS: Class label smoothing – using class label smoothing for sigmoid activation
- LS:类标签平滑 – 使用类标签平滑进行 sigmoid 激活
- CBN: CmBN – using Cross mini-Batch Normalization for collecting statistics inside the entire batch, instead of collecting statistics inside a single mini-batch
- CBN: CmBN – 使用交叉小批处理规范化收集整个批处理中的统计信息,而不是在单个小批处理中收集统计信息*
- CA: Cosine annealing scheduler – altering the learning rate during sinusoid training
- CA:协和素退火调度器 – 改变正弦训练中的学习速率*
- DM: Dynamic mini-batch size – automatic increase of mini-batch size during small resolution training by using Random training shapes
- DM:动态小批量尺寸 – 使用随机训练形状在小分辨率训练期间自动增加小批量大小
- OA: Optimized Anchors – using the optimized anchors for training with the 512×512 network resolution
- OA:优化的锚点 – 使用优化的锚点进行 512×512 网络分辨率的训练*
- GIoU, CIoU, DIoU, MSE – using different loss algorithms for bounded box regression
- GIoU、CIoU、DIoU、MSE – 对边界框回归使用不同的损失算法
Further study concerns the influence of different Bagof-Specials (BoS-detector) on the detector training accuracy, including PAN, RFB, SAM, Gaussian YOLO (G), and ASFF, as shown in Table 5. In our experiments, the detector gets best performance when using SPP, PAN, and SAM.
进一步研究涉及不同的巴戈夫特辑(BoS-检测器)对检测器训练精度的影响,包括PAN、RFB、SAM、高斯YOLO(G)和ASFF,如表5所示。在我们的实验中,检测器在使用 SPP、PAN 和 SAM 时获得最佳性能。
Table 4: Ablation Studies of Bag-of-Freebies. (CSPResNeXt50-PANet-SPP , 512x512).
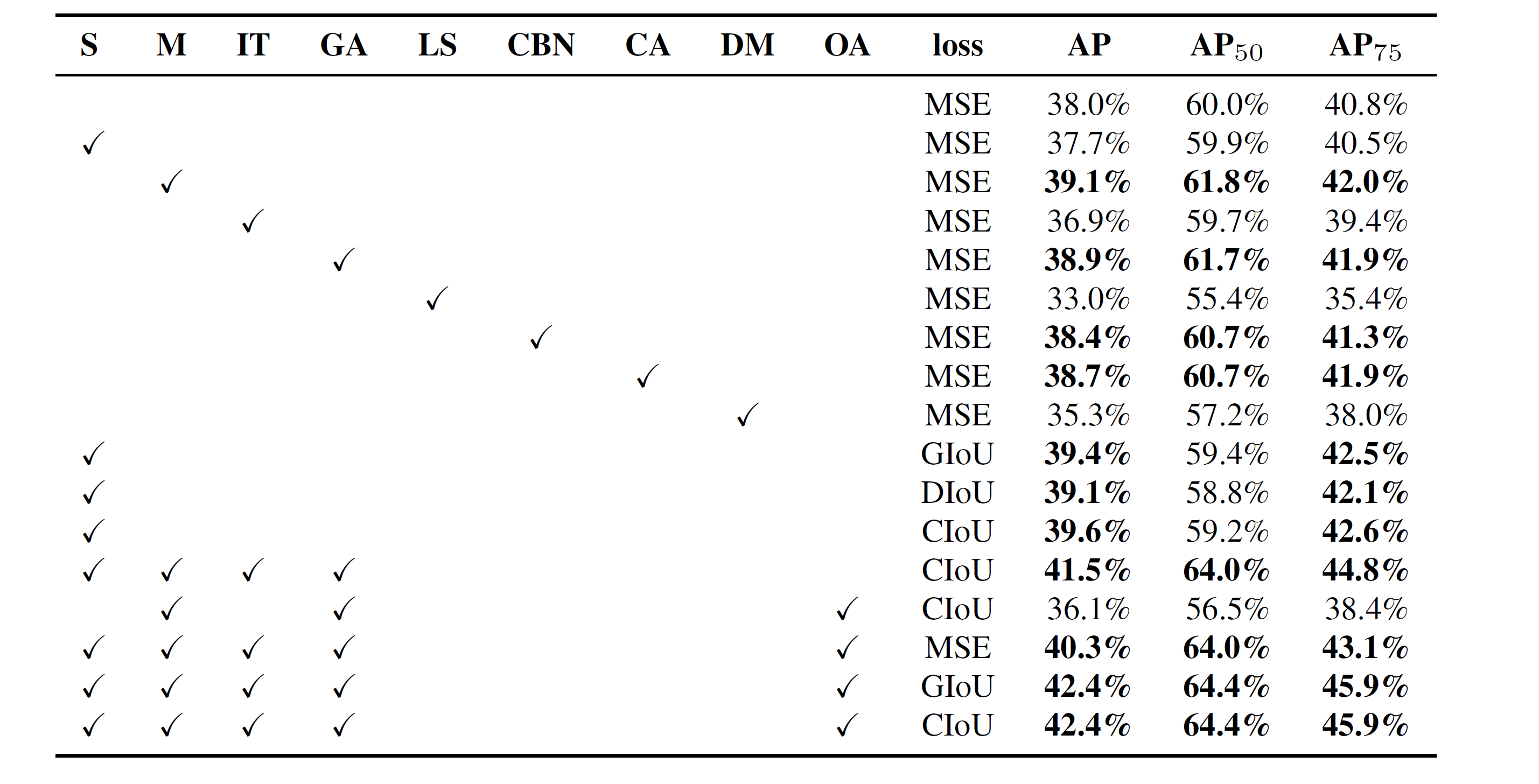
Table 5: Ablation Studies of Bag-of-Specials. (Size 512x512).

4.4. Influence of different backbones and pretrained weightings on Detector training
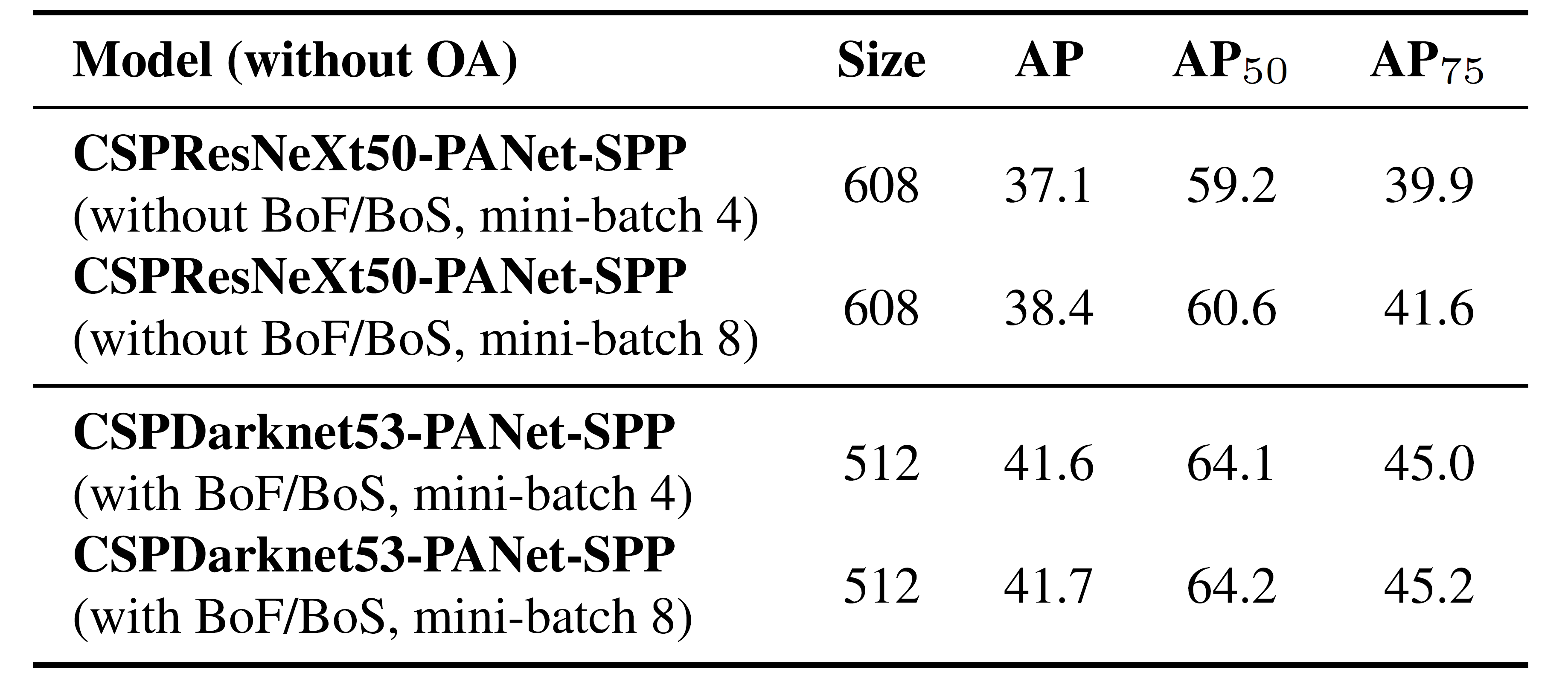
Further on we study the influence of different backbone models on the detector accuracy, as shown in Table 6. We notice that the model characterized with the best classifica- tion accuracy is not always the best in terms of the detector accuracy.
最后,我们分析了在不同最小批量大小下训练的模型所获得的结果,结果如表7所示。从表7所示的结果中,我们发现在添加BoF和BoS训练策略之后,最小批量大小几乎没有影响在检测器的性能上。该结果表明,在引入BoF和BoS之后,不再需要使用昂贵的GPU进行训练。换句话说,任何人都只能使用传统的GPU来训练出色的探测器。
Table 7: Using different mini-batch size for detector training.
表7:使用不同的小批量对于检测器训练。
5.Results
Comparison of the results obtained with other state-of-the-art object detectors are shown in Figure 8. Our YOLOv4 are located on the Pareto optimality curve and are superior to the fastest and most accurate detectors in terms of both speed and accuracy.
得到的结果与其他先进的目标检测器的比较如图8所示。我们的yolo4位于Pareto optimality曲线上,在速度和准确性方面都优于最快和最精确的探测器。
Since different methods use GPUs of different architectures for inference time verification, we operate YOLOv4 on commonly adopted GPUs of Maxwell, Pascal, and Volta architectures, and compare them with other state-of-the-art methods. Table 8 lists the frame rate comparison results of using Maxwell GPU, and it can be GTX Titan X (Maxwell) or Tesla M40 GPU. Table 9 lists the frame rate comparison results of using Pascal GPU, and it can be Titan X (Pascal), Titan Xp, GTX 1080 Ti, or Tesla P100 GPU. As for Table 10, it lists the frame rate comparison results of using V olta GPU, and it can be Titan V olta or Tesla V100 GPU.
由于不同的方法使用不同体系结构的GPU进行推理时间验证,我们在常用的Maxwell、Pascal和VoltaArchitecture体系结构的GPU上运行YOLOv4,并将它们与其他先进的方法进行了比较。表8列出了使用Maxwell GPU的帧率比较结果,可以是GTX Titan X(Maxwell)或Tesla M40 GPU。表9列出了使用Pascal GPU的帧率比较结果,它可以是Titan X(Pascal)、Titan XP、GTX 1080 Ti或Tesla P100 GPU。表10列出了使用VoltaGPU的帧率对比结果,可以是Titan Volta,也可以是Tesla V100 GPU。
6. Conclusions
We offer a state-of-the-art detector which is faster (FPS) and more accurate (MS COCO \(AP_{50...95}\) and \(AP_{50}\) ) than all available alternative detectors. The detector described can be trained and used on a conventional GPU with 8-16 GB-VRAM this makes its broad use possible. The original concept of one-stage anchor-based detectors has proven its viability. We have verified a large number of features, and selected for use such of them for improving the accuracy of both the classifier and the detector. These features can be used as best-practice for future studies and developments. 我们提供最先进的检测器,其速度(FPS)和准确度(MS COCO \(AP_{50 ... 95}\) 和 \(AP_{50}\) )比所有可用的替代检测器都高。所描述的检测器可以在具有8-16GB-VRAM的常规GPU上进行训练和使用,这使得它的广泛使用成为可能。单阶段基于锚框的检测器的原始概念已证明其可行性。我们已经验证了大量特征,并选择使用其中的一些特征以提高分类器和检测器的准确性。这些功能可以用作将来研究和开发的最佳实践。
7. Acknowledgements
The authors wish to thank Glenn Jocher for the ideas of Mosaic data augmentation, the selection of hyper-parameters by using genetic algorithms and solving the grid sensitivity problem https://github.com/ultralytics/yolov3.
作者要感谢Glenn Jocher进行Mosaic数据增强的想法,通过使用遗传算法选择超参数并解决网格敏感性问题的方法https://github.com/ultralytics/yolov3.10。